概览
本项目仍处于活跃开发阶段,可能包含尚未发现的缺陷。欢迎通过 Issue 和 PR 提交反馈与贡献。
AgentGuard 是一套面向 AI Agents 的零信任安全防护基座。它可以集成到现有智能体框架中,在智能体运行全流程中提供可配置的安全防护能力:每次调用大模型前、大模型输出后、工具调用前、工具执行完成后,都可以进行识别、拦截、升级处理或记录。同时,AgentGuard 也支持通过可插拔自定义审计器对已存储运行轨迹进行事后审计。
目前,AgentGuard 已覆盖 Anthropic 的 Zero Trust for AI Agents 中强调的多个关键技术点,包括访问控制与权限管理、可观测性与审计,以及行为监控与响应。
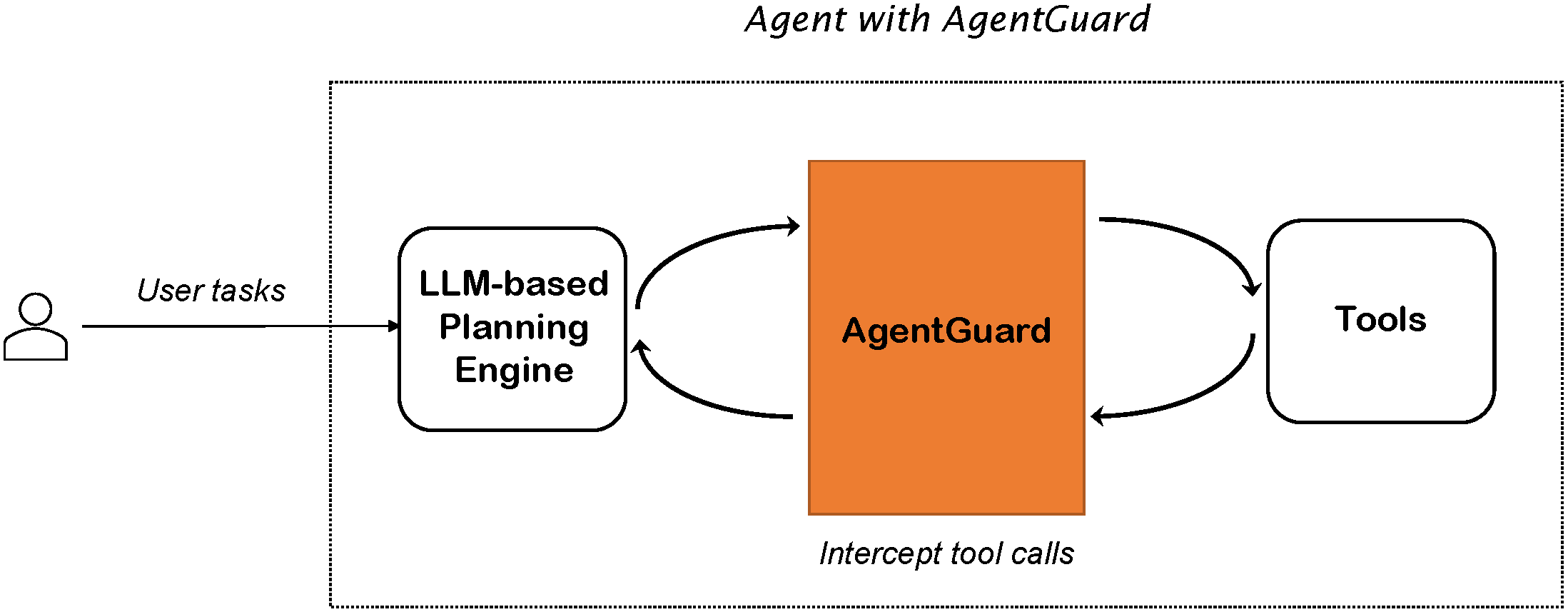
AgentGuard 提供什么
多阶段安全防护
AgentGuard 不只检查单次工具调用,而是可以贯穿智能体运行过程。在 LLM 输入、LLM 输出、工具调用和工具结果等阶段,它都可以根据配置的安全策略进行检查,并返回 allow、deny、升级审核或记录等结果。
模块化安全策略
AgentGuard 通过统一的 plugin 架构适配规则型和模型型安全策略。当前版本内置了一个名为 rule_based_plugin 的 server plugin,支持通过可配置的 DSL 规则识别并拦截工具调用中的安全风险,避免高风险工具调用真正执行。
单工具与跨工具链路保护
AgentGuard 既可以判断单次工具调用,也可以判断跨步骤攻击链。通过存储运行时上下文,它可以检测这类行为:
- 从数据库读取数据,然后发送邮件
- 读取敏感文件,然后上传到外部 HTTP 端点
- 外部输入最终流入 Shell 命令
无缝集成现有智能体框架
AgentGuard 位于大模型规划引擎与工具之间,不替代智能体的规划、推理或任务编排逻辑。它为主流智能体框架提供 adapter,用户无需修改框架内部实现,也不用大规模重构现有智能体,只需少量代码即可接入。
当前支持的框架包括:
- LangChain
- AutoGen
- OpenAI Agents SDK
- Openclaw
可视化策略配置与审计
AgentGuard 提供 Web 控制台用于管理智能体。控制台支持交互式策略配置、运行时监控、待审批请求处理和审计记录查看。对于触发策略的工具调用,用户可以查看命中的规则、风险分数、最终决策以及原始事件或决策 JSON。
集中式中控管理
AgentGuard 采用集中式中控架构治理分布式智能体进程。智能体可以部署在网络中的多个节点,而策略配置、运行时监控和审计流程由中控服务集中管理。这适合需要统一治理大量智能体资产的组织场景。
AgentGuard 设计架构
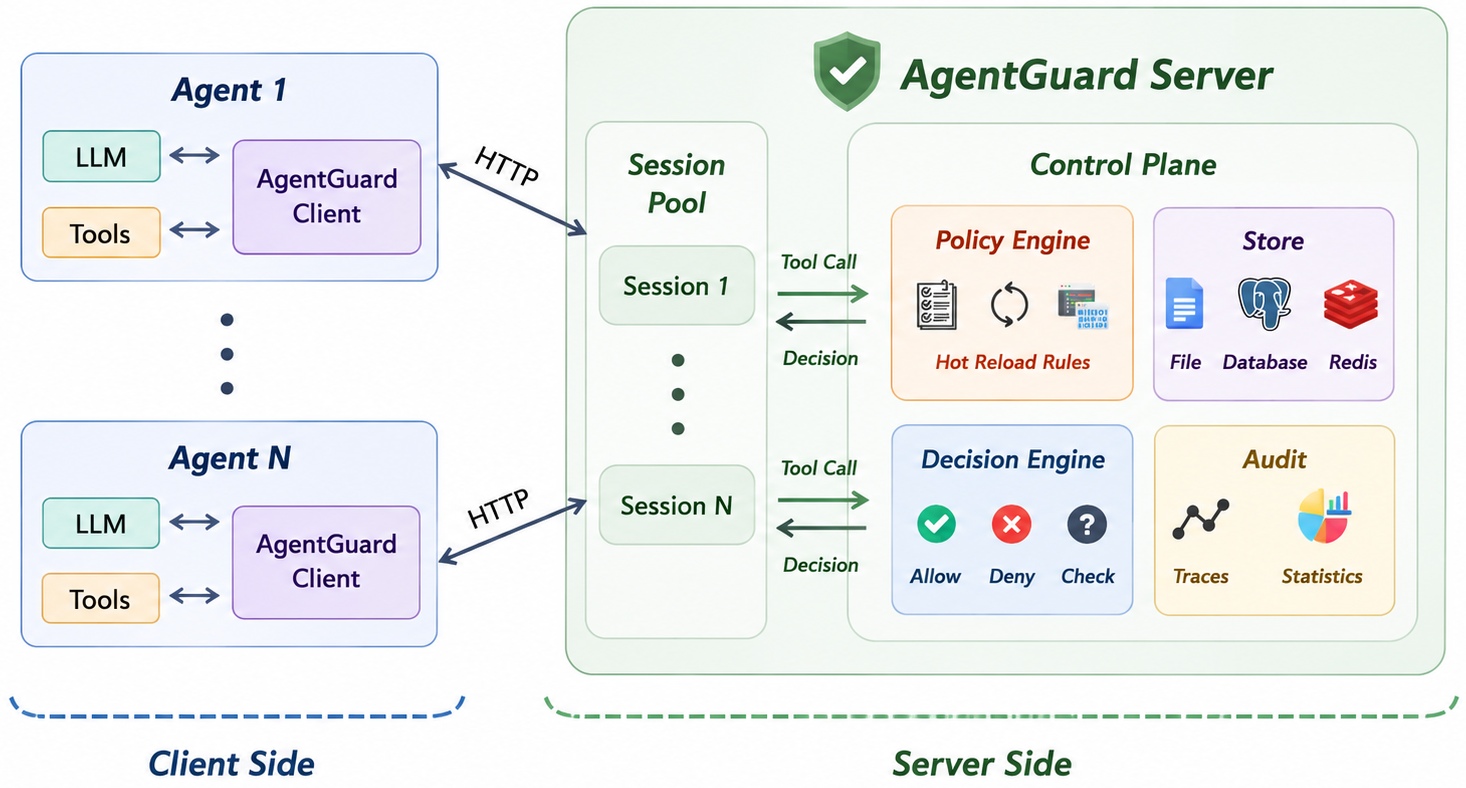
整体上:
- 客户端:集成到智能体框架中,拦截 LLM 与工具事件,执行轻量级本地过滤,并在需要时把事件发送到服务端。
- 服务端:接收客户端运行时信息,执行配置的 plugin 与策略评估,返回决策,并存储 trace 供监控和审计使用。
- Plugins:扩展客户端或服务端的运行时检测能力。
- 自定义审计器:对已存储 trace 做事后分析,支持复核、合规与事故排查。
什么时候使用 AgentGuard
当智能体可以接触真实系统资源时,AgentGuard 的价值最明显,尤其包括:
- 邮件、HTTP、消息发送等外发工具
- Shell 或系统命令工具
- 文件系统读写工具
- 数据库读写工具
- 不可信输入可能影响后续动作的工作流
即使没有工具调用,AgentGuard 依旧可以在 LLM 输入和输出阶段进行安全风险识别与拦截。如果智能体只是低风险对话场景,AgentGuard 可以按需接入;如果智能体会处理敏感 prompt、不可信输入、受监管内容、系统数据,或会影响系统、数据和外部目标,AgentGuard 就可以提供清晰、可配置、可审计的控制层。